YOLOv8 + DINOv2: Injecting Global Semantics for Better Detection

In the world of computer vision, we are often forced to choose between two extremes: Speed and Understanding. YOLO models can detect an object in milliseconds, but they learn purely from the bounding box labels. They don't inherently "know" what a dog is; the model just knows the texture of particular dogs learned from limited examples.
On the other hand, Foundation Models like Meta's self-supervised DINOv2 have read the visual internet, trained over 150M images. They understand shape, occlusion, parts, and semantic relationships without ever seeing a single label. But they are heavy and slow.
In this project, I created a hybrid YOLOv8-DINO architecture. Unlike other complex fusion methods, my approach is elegant and lightweight: I inject the global "understanding" of the image from DINOv2 directly into the deepest layer of YOLO. This acts like a "hint" for the detector. It tells YOLO what is in the scene (e.g., "Industrial Equipment"), allowing the YOLO head to focus on where it is.
The Architecture Strategy
Standard YOLOv8 uses a CSP-Darknet backbone to extract features, which is an enhanced version of the architecture used in earlier YOLO versions. It's fast and effective but lacks a "global" understanding of the image.
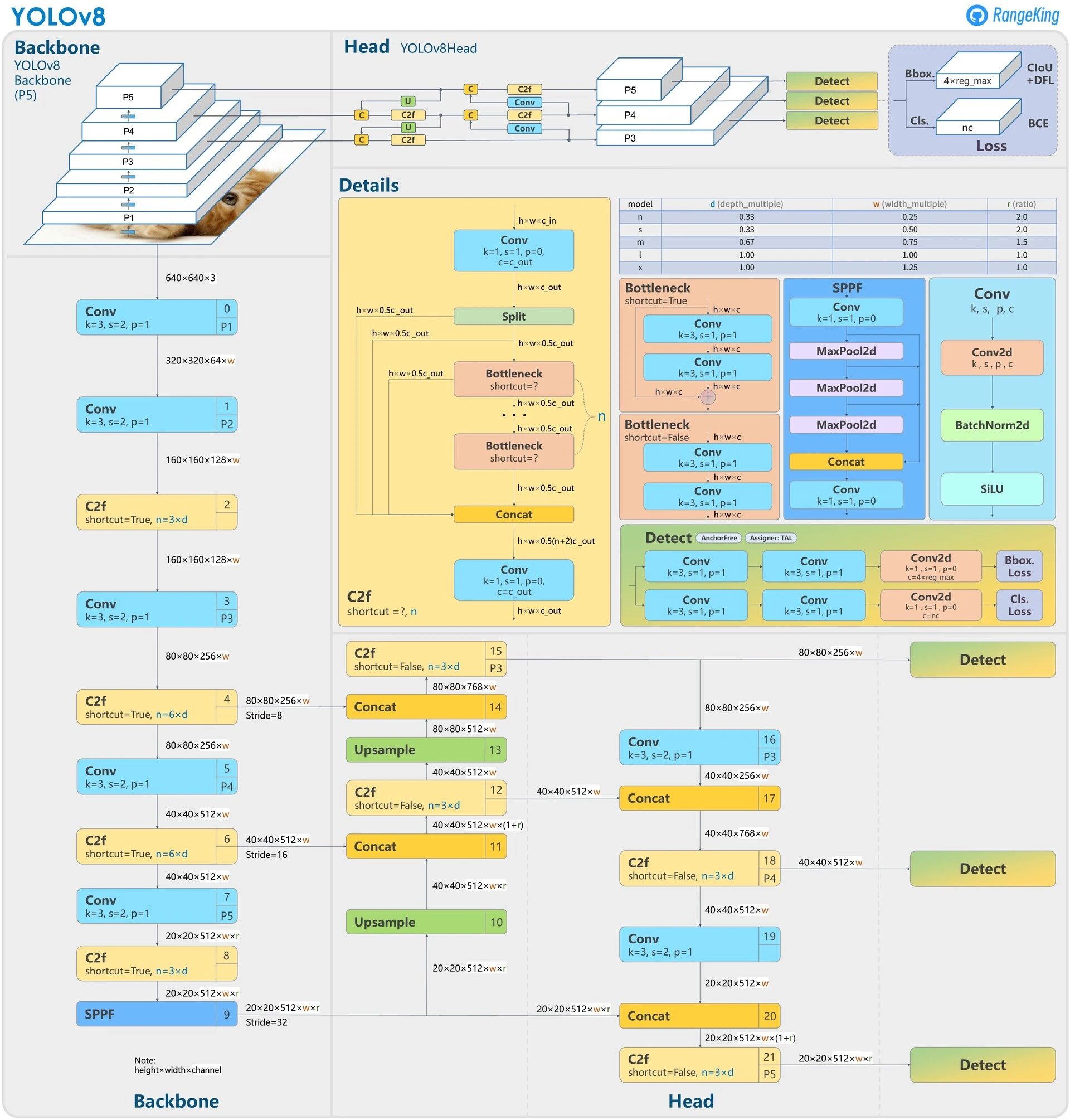
We modify the standard YOLOv8 YAML to introduce a secondary path:
- Path A (Standard): The image flows through the standard CSP-Darknet backbone (Layers 0-10) to extract spatial features.
- Path B (The Bypass): We grab the original raw image at Layer 0 and send it to a DINOv2 Module.
- Global Context Injection:
- DINOv2 processes the image and outputs a Global Embedding (a rich vector summarizing the whole image).
- We project and upsample this vector to match the size of the YOLO feature map.
- Effectively, we are painting the YOLO features with a "Context Layer."
Modifications in the Architecture
I introduced a ConvDummy layer at index 0. This allows me to pass the raw image from the start of the network directly to the DINO module at the end (`[-1, 10]`) without processing it through YOLO's layers first.
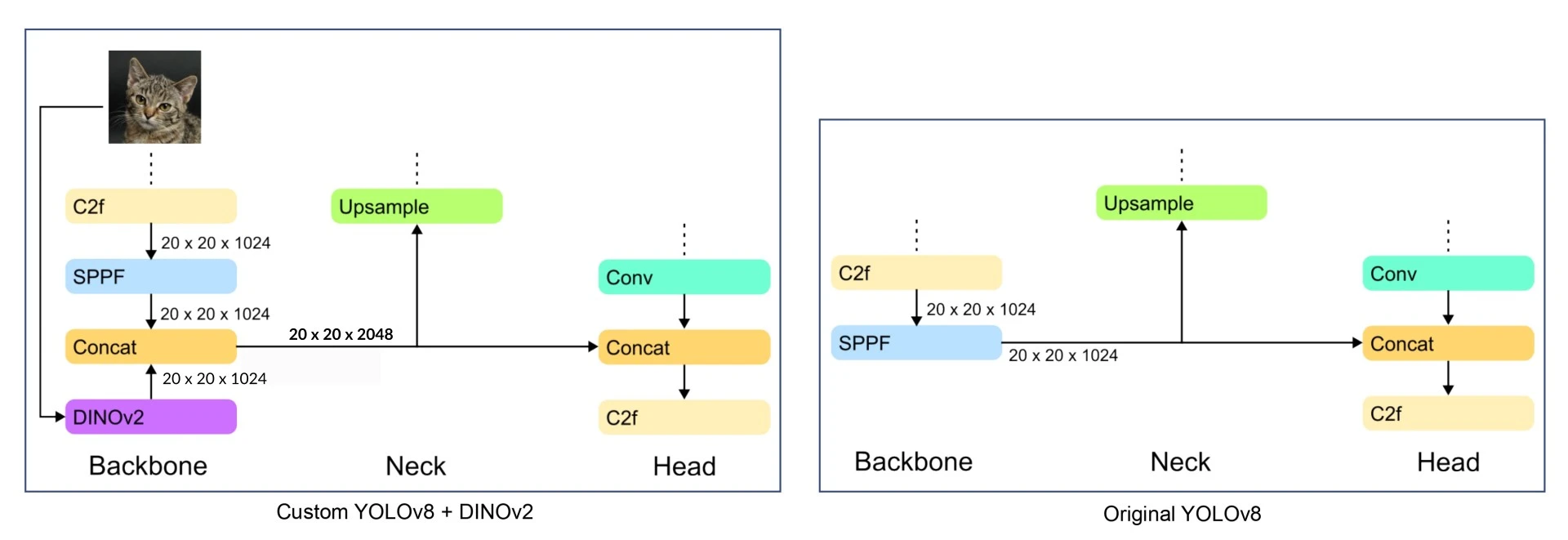
Here is the modified YAML configuration for the backbone:
# YOLOv8.0n backbone (Modified)
backbone:
# [from, repeats, module, args]
- [-1, 1, ConvDummy, []] # 0: Pass raw image (Args removed, inferred auto)
- [-1, 1, Conv, [64, 3, 2]] # 1: Start of standard YOLO backbone
# ... [Standard Layers 2-9] ...
- [-1, 1, SPPF, [1024, 5]] # 10: End of YOLO backbone (Stride 32)
# The Fusion
- [0, 1, DINOv2, [1024]] # 11: Take Raw Image (from 0), get Global Context
- [[-1, 10], 1, Concat, [1]] # 12: Concatenate SPPF (Spatial) + DINO (Global)
Implementation: The Code
The core of this method is the Global-to-Spatial Broadcast. DINOv2 gives us a 1D vector (embedding). We project it and upscale it to match the YOLO feature map size.
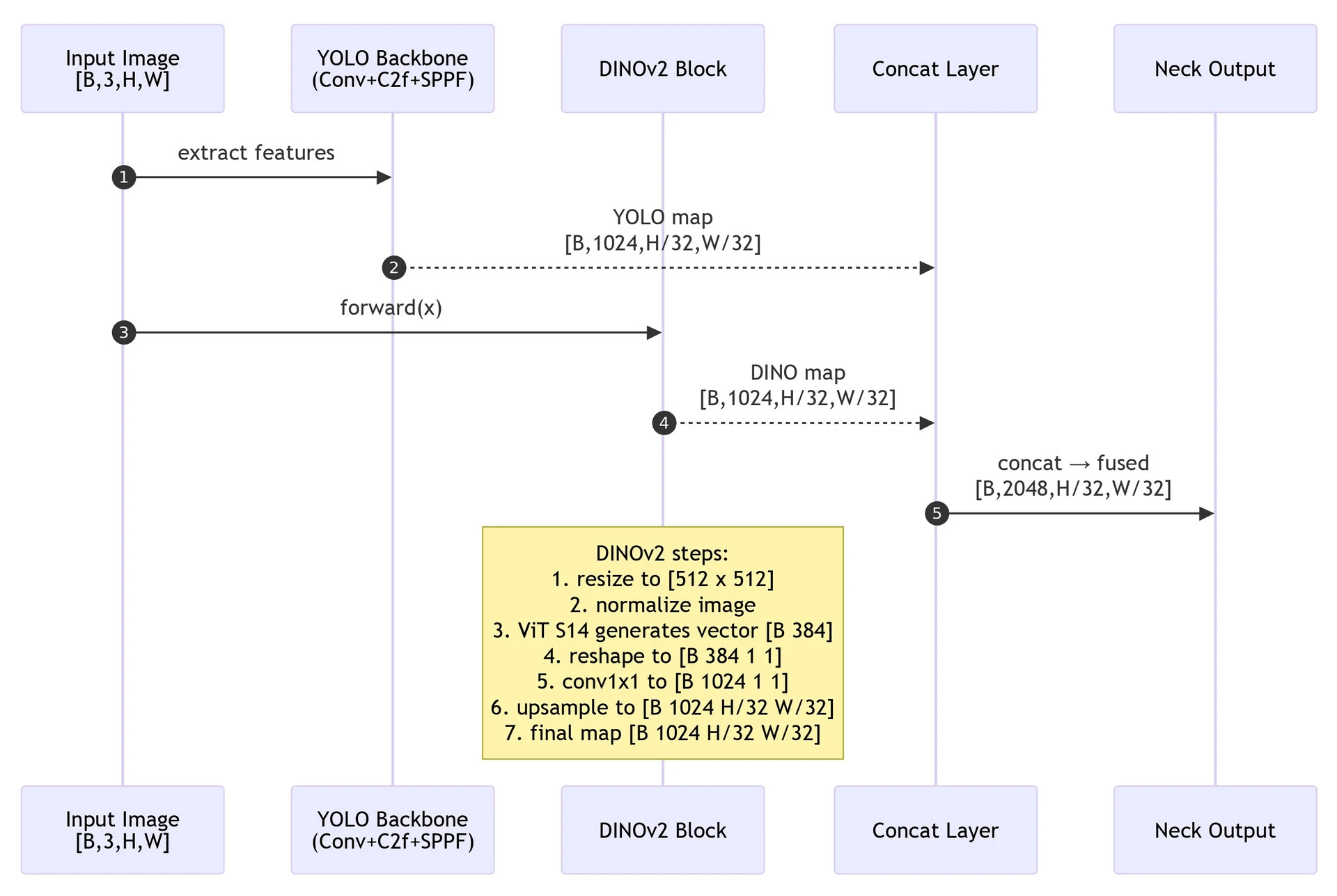
Here is the implementation of the DINO module:
import torch
import torch.nn as nn
import torchvision.transforms as T
import warnings
import os
import contextlib
class DINOv2(nn.Module):
def __init__(self, c1, c2):
super().__init__()
# Load Frozen DINOv2
with warnings.catch_warnings():
warnings.filterwarnings("ignore") # We suppress stdout to keep logs clean
with open(os.devnull, 'w') as fnull, contextlib.redirect_stdout(fnull), contextlib.redirect_stderr(fnull):
self.model = torch.hub.load("facebookresearch/dinov2", "dinov2_vits14")
# Projector: Maps DINO embedding (384) to YOLO channels (c2), We define this in init so weights are trained!
self.projector = nn.Sequential(
nn.Conv2d(384, c2, kernel_size=1),
nn.Upsample(scale_factor=1, mode='bilinear')
)
def preprocess(self, tensor, imgsz=512, patch_size=14):
# Resize to be divisible by patch_size (14)
imgsz = round(imgsz / patch_size) * patch_size
transform = T.Compose([
T.Resize((imgsz, imgsz), antialias=True),
T.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
return transform(tensor)
def forward(self, input_tensor):
# 1. Extract Global Embedding
with torch.no_grad():
processed = self.preprocess(input_tensor)
embedding = self.model(processed) # Shape: (Batch, 384)
# 2. Broadcast to Spatial Dimensions, (Batch, 384) -> (Batch, 384, 1, 1)
embedding = embedding.unsqueeze(-1).unsqueeze(-1)
# 3. Align with YOLO Size (Stride 32)
h, w = input_tensor.shape[2] // 32, input_tensor.shape[3] // 32
# 4. Project and Upsample, Resize the 1x1 embedding to HxW feature map
feature_map = nn.functional.interpolate(
self.projector[0](embedding),
size=(h, w),
mode='bilinear',
align_corners=False
)
return feature_map
And the ConvDummy Module, a simple utility to allow the YAML config to route the raw input image.
class ConvDummy(nn.Module):
# Accepts whatever args the parser sends, but ignores them
def __init__(self, c1, c2, *args, **kwargs):
super().__init__()
def forward(self, x):
return x
Why This Works
By injecting the Global Embedding rather than patch features, we provide the YOLO head with a "scene summary."
- Standard YOLO: Sees "edges" and "circles."
- YOLO + DINO: Sees "edges" and "circles" + "Context: This is a factory floor."
This extra context helps eliminate false positives and improves detection consistency in complex environments where local texture isn't enough.
Experimental Results
I evaluated the hybrid model on the SODA-D (Small Object Detection dAtaset). The results were significant. Fusing DINOv2 with YOLO resulted in almost a 60% increase in accuracy (mAP50) compared to the standard YOLOv8n baseline, using the same training parameters (25 epochs, batch size 16).
| Model | Epochs | Batch Size | Images | Precision (P) | Recall (R) | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|---|
| YOLOv8 + DINOv2 | 25 | 16 | 5017 | 0.547 | 0.420 | 0.434 | 0.206 |
| YOLOv8 (Baseline) | 25 | 16 | 5017 | 0.372 | 0.303 | 0.271 | 0.122 |
The table above shows a jump in mAP50 from 0.271 to 0.434. This validates the hypothesis that the global semantic context provided by DINOv2 significantly aids in detecting small, hard-to-distinguish objects that a standard CNN might miss.
Setup & Training
To replicate this locally, you cannot just use pip install ultralytics. You need to modify the source code to "teach" YOLO about our new DINOv2 module.
1. Clone and Install in "Editable" Mode
This allows you to modify the code and have changes take effect immediately.
git clone https://github.com/ultralytics/ultralytics.git
cd ultralytics
pip install -e .
2. Inject the Custom Classes
- Modify
ultralytics/nn/modules/conv.py: Paste theConvDummyclass code at the bottom of this file. AddConvDummyto the__all__list at the top. - Modify
ultralytics/nn/modules/block.py: Paste theDINOv2class code at the bottom of this file. AddDINOv2to the__all__list at the top.
3. Register the Modules in tasks.py (Crucial Step)
The YOLO YAML parser lives in ultralytics/nn/tasks.py. It needs to know your new classes exist. Open the file and explicitly import your new classes:
from ultralytics.nn.modules.block import DINOv2
from ultralytics.nn.modules.conv import ConvDummy
4. Run Training
Duplicate the standard config yolov8.yaml, rename it to yolov8-dino.yaml, replace the backbone, and run training:
from ultralytics import YOLO
# Load the model using our custom YAML
model = YOLO("yolov8-dino.yaml")
# Train
model.train(
data="coco8.yaml", # or your_custom_dataset.yaml
epochs=100,
imgsz=640, # resizing to 644 might help align patches!
batch=16,
device=0
)